Design for Efficiency-Process & Design Co-optimization
Hockchen@digwise-tech.com 2020/11/6
近臨界電壓(Near-VT)系統與客製化(custom cell)需求並非單純元件庫供應商與晶片設計間兩 者的供需問題而已,如何掌握底層製程 SPICE 模型不準確、製程變異性分析、科學化元件庫的變 異性模型、製程與實體設計配方參數的整體優化、後矽的製程配方調校與量產策略與對後續元件庫 開發優化的正向反饋是我們未來可以思考規劃的「創新技術」與「創新服務」核心。
1.極致能效設計(Design for Efficiency)
1.1.近臨界電壓系統(Near-VT System)
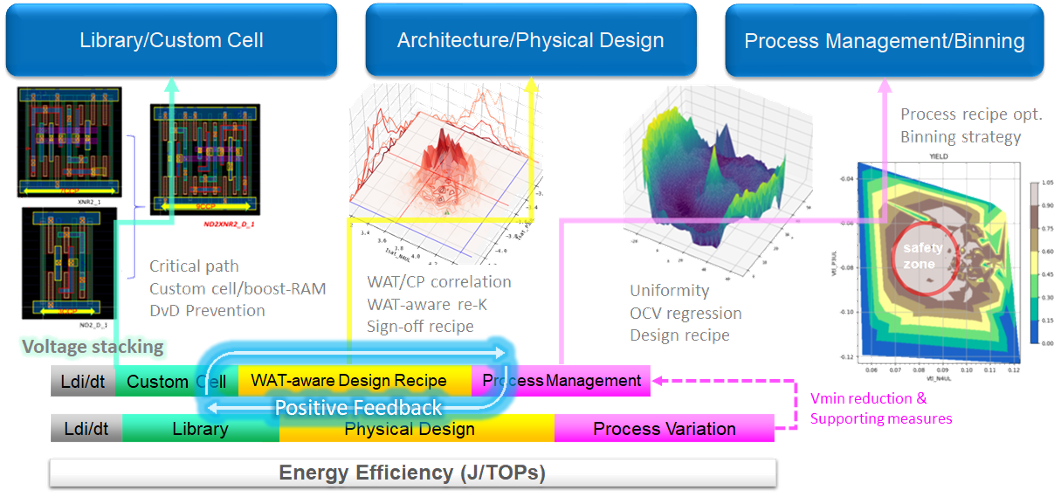
若定義「能效(efficiency)」為每單位運算下所需要的能量(J/TOPs),一般想要提升能效最有用的方法是降低晶片工作電壓(Vmin)。以往我們把整個影響能效的許多主要因素拆解(break-down)成幾個成份: 一個是在晶片外面的晶片封裝(package)與電源供應(voltage source),其次是所選用的元件庫(library)以及我們自己的功力,包括晶片架構(architecture)與實體設計(physical design)的能力,剩下就聽天由命看晶圓廠的能力。然而今天我們不能再這樣子分工了,未來晶片設計與晶圓廠之間應該更緊密的分享資料與互相合作,在降Vmin的過程我們必須有一些創新的設計方法與配套措施(supporting measures)。
1.2.串接電壓源系統(Voltage-stacking System)
早期我們做晶片多核心(multi-core)的時候,最怕的就是package RLC,因為當晶片同時有多個核平行運算的時候電流會很大,能否提供足夠的大電流是一回事,而當一個大電流通過這個元件時電壓降噪音(Ldi/dt)是被放大的。因此,晶片多核心運算有另外一種思路稱「串接電壓源(Voltage-stacking)」,它是把晶片串接起來,也就是說我們會把Vmin降到盡可能的低(例如低於350mV)。因為串聯結構電流是固定的,所以通過同樣的元件(package RLC)更多串接的晶片會把這些noise均攤掉。
晶片間的串接結構(voltage-stacking)形成了「電流動態平衡」的閉迴路系統(close loop),先天有良好對抗製程偏移的自我補償特性(self-voltage compensation),例如當有因製程偏慢的晶片在串接系統中,其跨壓會被動態提升以維持整個系統的電流平衡。然而其致命傷是因為熱或製程偏移導致的漏電流,因為串接系統為平衡電流反而使效能因漏電流加劇而降級的晶片分到更低的跨壓。此外任何非晶片運作生成的電流對串接系統極容易產生非預期的反效果,因此傳統的低電壓調節技術(例如,CG/DVFS/AVS)都變得非常不直覺,演算法必須對系統整體調整而非針對單晶片個別調整。針對這件事情目前論文數不多,但是它是一個值得研究的方向。

1.3.晶圓廠製程掌控能力
下圖是普遍晶片量產時可能遇到的製程平坦性問題(process uniformity),無論晶圓廠優劣或對製程工藝掌握如何,初期晶圓的平坦性大致都會呈現系統級的諧振(harmonic vibration),例如大者有非常明顯的甜甜圈或同心圓漣漪(polish/spin pattern),也有如火山錐的大斜坡或是如墨西哥帽的陡峭邊緣(sputter/film/holder)。中間程度者有如光刻過程的干涉網格狀或蛋槽的圖騰(litho/shot),程度輕者可能包含實體設計過程中電路佈局等綜效所造成的等效電壓降(density/metal/power/bump),其它細微者還有如摻雜與蝕刻等等製程綜效累積的結果(doping/etching)等等,這些影響可能都强過隨機性。

1.3.1. 系統級缺陷(Systematic Defect)
隨著有更多晶圓資料的累積,我們可以觀察當多數晶圓有著相同趨勢的圖案(pattern)後,即可逐漸釐清製程中誰是關鍵大頭(bottleneck)而不是互踢皮球。一般薄膜、CMP或各式製程設備會以不只一台機器批次執行,因此資料往往會出現分群的現象,但若當我們跑了上百片晶圓都有相同傾斜、漣漪或花瓣圖樣時,那案情可能就不單純了! (因為除非其中有一道大家都必須通過它的關鍵站點/流程)。

若我們將所有關於晶圓整體(WIW)性能的均值排序,例如CP時能得到的SIDD、RO、critical path頻率等等幾項參數的加權指標,可以發現晶片性能好壞已經先反應在晶圓級測試資料中。資料經常會呈現數個較小的分群或幾個更大的分群,且往往有相同的資料圖騰或缺陷特徵(pattern),因此當資料沒有分群將更顯怪異。我們可能會懷疑,噴嘴頭會全部堵一邊嗎? 支架(holder)都側傾一邊嗎? 都必須通過某幾台珍貴的機器嗎(e-beam)? 還是整座晶圓廠地基傾斜呢? 而晶圓廠之間能力的差異就是如何產生這些數據,分析這些數據並透過機器學習(machine-learning)或深度學習(deep-learning)以掌握各製程之間的關聯性並加以補償或優化。

不同晶圓廠間因為生產機器設備、製程方法與流程等差異,往往會有各自獨特的製程特徵而且非常明顯。而晶片位於晶圓的不同位置上可能呈現極端的效能差異(例如RO的頻率),一片晶圓的3σ分佈可能橫跨幾乎等效於全域的FF至SS corner的變異性。

1.3.2. WAT採樣點不足(WAT Sampling Issue)
下圖顯示晶圓級幾個物理特徵(feature)的曲面(例如SIDD與晶片內RO的均值),我們以傳統量產時幾個離散WAT測試點(13 site map)與其鄰近5×7(一個shot)區域的晶片來看,就可以知道傳統WAT數據是多麼不可靠了(既使是花費更高成本用所謂的78點full map)!

採樣點(sampling)不足會導致製程工程師團隊一個麻煩,例如所謂的WAT Isat/Vtl均值(mean)或中位數(median)「達標(on-target)」,事實上很有可能超過60%樣本是落在極大或極小的值域且其性能梯度(gradient)非常大,因此所謂的均值或中位數很有可能根本沒sample! 也就是說WAT數據變得非常「以偏概全」且不牢靠,我們很容易錯過真實最佳配方。而晶圓廠與實體設計如何分析局域的性能梯度並優化製程或調整設計餘量(margin),直接影響晶片的能效(efficiency),這裡的能效包含了晶片性能、競爭力、與產能(productivity)。這有賴晶圓廠與實體設計雙方共享更多測試數據,透過跨資料維度的關聯性分析與機器學習(或深度學習)來提升資料的可信度。

2. 實體設計的創新(Innovation in Physical Design)
2.1. 製程分析的創新(Process Analysis)
隨著對近臨界電壓系統(Near-VT System)技術的需求,晶片設計自己也必須具備製程分析與管理的能力(process management),不能再只單方面依賴晶圓廠提供的通用設計規則與條件限制。晶片設計也要有能力去分析WAT,並且根據WAT與後矽(post-silicon)測量結果去定義實體設計配方與時序簽核策略(timing sign-off)。當前製程工藝下,各家晶圓廠SPICE模型與後矽(post-silicon)資料都有明顯的偏差,若只是執行低電壓時序庫萃取(timing re-K)並依此進行實體設計可能會導致失敗。因此標準元件庫的時序特徵萃取必須分析WAT與其SPICE模型的偏移(mean shift),並依據WAT與SPICE關聯性分析具體提供校準方案、關鍵時序庫(majority corner)與相關實體設計防守策略(並依據實際市場需求與場景調整)。

2.2. 晶片關鍵路徑與SPICE模擬的關聯性分析
針對晶片電路的瓶頸(critical-path),我們可以分析並根據所使用關鍵元件各個物理參數(instance、power、area等)的占比(usage)與排序做優化,比較關鍵的IP例如memory可以透過charge-pump以保證電路存/取時的正常操作,並且對clock-network或者一些dynamic-IR比較有疑慮的點來做防守。從與許多晶圓廠於深次微米製程之量產經驗,無論製程工藝優劣,量測數據往往都無法與所提供之SPICE模型吻合(且往往偏慢)。這導致一開始有些晶圓廠可能會急著要先把製程配方(recipe)往FF方向調整(尤其是die-buy的客戶)。對晶圓廠而言他們可以較容易出貨給客戶較多「速度達標」的單晶片,但其他副作用例如漏電流(leakage)所衍生「系統能效降級」的問題卻需要客戶設法承擔,這樣的調整對整體系統層面來說並不是真實的優化。
以下圖來說明,製程調校(process tuning)在leakage維度是log增幅,再加上溫度的因素會更不好控制。事實上若晶圓廠所提供的SPICE模型(包括local variation)够準確,基於製程偏移-電壓補償的等效性,製程參數或反映在晶片速度的不達標並不可怕,透過電壓補償的手法在速度與leakage維度都是可控/可預測的〫因此,真正的最佳製程與實體設計配方應該是: 晶圓廠必須開誠布公,使製程與晶片設計雙方協調好並掌握最真實的製程參數,透過真實的防守策略進行實體設計並輔以系統層級的補償方式來「拆分對抗」變異性的難題,不要過度設計(over design)。系統設計端至少可以從實體設計配方(design recipe)與時序簽核方法學(timing sign-off)檢討,搭配晶片效能評等(binning)與電壓-頻率補償(voltage-frequency compensation)兩種策略協同優化,以降低實體設計因為over design所導致的競爭力下降(也導致所設計的晶片不夠efficient)。

2.3. 客製化元件的創新(Custom Cell/re-K)
藉由製程分析的創新(Process Analysis),我們可以根據前面所提到個別晶圓廠製程上的不同弱點(1.3.2),進行客製化元件開發(custom cell)與優化,並根據WAT的偏移修正元件庫時序萃取(timing re-K)並優化實體設計防守配方(design/sign-off recipe)。
2.3.1. 設計與元件特徵萃取(Design/Library Metric Extraction)
透過特徵萃取並觀察其趨勢,洞悉元件參數與實體設計工具/演算法整體配合的不足,才是數據分析的優勢與開發關鍵元件庫的方向(標準元件庫開發商也不都是省油的燈)。我們可以依據晶片架構與市場競爭力需求,針對不同功能性單元提供適配的關鍵元件庫規劃與開發,在滿足能效的市場規格下進一步優化面積與功耗,提升自己產品或客戶的價值。

2.3.2. 元件架構的創新
透過電路關鍵路徑與關鍵瓶頸分析排序的元件優化與開發策略,根據實際系統任務與市場需求,以統計的方式進行關鍵元件重新開發並實質收到巨大效果。實質的電路架構優化,包括針對晶片電路關鍵路徑上的元件做電性上驅動力平衡的補償、針對時脈平衡與穩壓(避免dynamic-IR)的時鐘樹元件調整、透過layout巧思的面積與功耗縮小、針對APR繞線問題的接腳位置優化、針對重複性與功能性的合併/整合(MEGA cell, DAC2020)並提供高度客製化元件的重新架構與再設計。

2.3.3. 針對功能/效能需求做適配性元件開發
一般最有效益的優化對象為暫存器(flip-flop)與時鐘樹元件(clock-tree cell),透過多位元暫存器堆疊除減少電容也需有效修正電訊號波形的歪斜(slew balance)、自帶耦合電容(de-cap)並搭配layout垂直排列以避免dynamic-IR,以及透過電路接腳位置的改善以減少實體設計繞線之間的疊代成本等等。其他比較可觀的優化可以針對電路任務/效能需求與市場規格做適配性的元件開發,例如提供不同高度(track)的元件並針對非時序瓶頸的區塊以細部優化面積與功耗。

3. 晶片內變異性分析(On-chip Variation Analysis)
3.1. 晶圓均勻一致性(Uniformity
在更早以前我們曾經有文章討論過晶片不平坦性的問題–ASIC Design之初(2)-我們在對抗甚麼?,在此,我們摘要如下三點。
3.1.1. 粗粒度諧波(Coarse-grained Harmonic)

我們以晶圓SIDD特徵曲面的反離散餘弦轉換(IDCT),從低頻到高頻的成份來解釋製程工藝中不平坦性的各個不同頻率成份。最低頻的成份包含前面第一章(1.3.1)所提到的傾斜(固定往某一側傾斜),很可能僅是由某幾道製程造成,例如薄膜或沉積不均。在稍微提高一些頻率可以看到每片晶圓都有相似同心圓的圖騰(pattern),這漣漪狀很可能是晶片在類似旋轉拋光時(polish/spin)專有的圖騰。這類比較低頻的諧波振盪(harmonic oscillator)圖案各家晶圓廠都有,只是程度優劣與改善應變能力不同的區別。
3.1.2. 細粒度諧波(Fine-grained Harmonic)
下圖也是幾乎所有晶圓廠都能看到的系統級圖騰,透過相同批次不同晶圓之間同物理量的疊加(去除隨機性),呈現的是晶圓在光刻過程光罩shot與shot之間的干涉圖樣(像冰箱裡的雞蛋盒),細部也可以很清楚看到光刻效應(Litho effect)除了電性上的影響(例如SIDD)也能看到實際對電路性能(或元件delay)的影響。在干涉的波峰位置SIDD偏大,而此時元件delay相對較小(偏快)。不過這個振盪的變異性相對較高頻且振幅較小,透過之前討論過的製程-電壓等效性原理(ASIC Design之初:章節2.4),一般在實體設計可以增加適當的設計餘量(design margin)來克服。

3.1.3. On-chip Variation
下圖是以更微觀的角度來看「非隨機性」的問題,我們可以透過環振電路(Ring-Oscillator, RO)反映晶片內部效能歪斜的情形,其中的效能梯度(performance gradient)是實體設計必須要扛的餘量(margin)。這也說明為什麼若晶片只有局域的製程監測器(process monitor)一般都不管用,只是花錢又浪費面積,設計餘量最重要的其實是處理「效能梯度」的問題。效能梯度可以想成是晶片供電之後先天有個等效電壓降(effective IR drop)不均的問題,無法用global corner應對(這個做法事實上既浪費晶片面積也無法解決梯度問題),因此我們必須確實防守這個「局部」且「非隨機性」的問題。這也是為何麼有些老經驗覺得用傳統OCV來做實體設計守備比較靠普的原因,我們常常說不清楚為何前一次量產沒事,然而用了新方法良率卻變差因此害怕而止步不前。

3.2. 對能效的影響(Efficiency Impact)
晶片能效(efficiency)不均是晶圓各種物理特徵曲面的不平坦所衍生的問題,若晶片在製造時位於晶圓上相對比較平坦的區域,那麼其晶片內時序變異(early & late)的分佈較小,反之OCV的分佈將非常大且不能以傳統LVF模型假設局域變異有隨機性因而能相互抵消(cancelation)的方式處理。下圖例舉三個晶片在晶圓不同位置所量測之動態表現,y軸代表量化的晶片性能指標,晶片在晶圓SIDD曲面高峰區(C區)有較高的Fmax但低頻可能跑不起來,麻煩的是donut B區還有個類似sin-wave的高低振盪,而邊緣區(A區)通常體質最差。

4. 製程與設計協同優化(Process & Design Co-optimization)
4.1. 製程監測電路整合(Process Monitor Integration)
在晶圓廠製程與晶片實體設計協同優化的流程中,關鍵的製程分析並不需要研發什麼高大尚的電路或花費昂貴的成本另外購置IP,重點應該放在: 如何「規劃」與「產生」所想分析的數據資料,以及如何進行跨資料維度的關聯分析(correlation)與建模(modeling)。透過資料科學的創新,掌握更精確的製程與設計參數,下面流程以一般常用的Ring-Oscillator(RO)為例。

RO的設計取決於我們想要得到甚麼樣的數據,例如: 為了跟SPICE對答案我們會多準備幾種單一元件組成的delay-line(若面積許可有時甚至會搭配數種不同driving),為了跟晶片效能有較佳的關聯性我們會嘗試組合幾種使用比率較高(有代表性)的元件(例如critical-path),為了能夠跟WAT有較好的關聯性我們會配置至少兩種P-stacking與N-stacking的元件,其他諸如為了取得對電壓較或對溫度較有敏感性的特徵我們會客製化一些特殊元件來當作RO的組成要件。
4.2. Co-optimization Flow
以目前各家晶圓廠的製程控制能力與配合度,實務面來看不太可能只靠系統端binning策略或電壓補償就可以明顯改善能效目標(J/TOPs)。下圖是給期許未來能搭載數據分析與製程控制能力的晶片設計公司一個建議的實體設計與製程協同優化的流程,目標是透過製程分析與機器學習(或深度學習)提出策略並正向回饋以優化元件庫與實體設計方法學,使每次疊代都能具體提升至少10%能效目標。

4.3. 晶片內變異性的設計餘量(OCV Margin)
實體設計須優先考慮真實的OCV防守餘量,雖然這只是局域的變異性(local variation)但却是晶片生產結果的大宗(majority),會發生且為非隨機性的變異(系統級),也應該是最低設計要求(minimum requirement)。基本的OCV需求若沒守住,global corner加再多設計餘量(margin),搭配怎麼優秀的binning或電壓補償可能都沒有用! 如下圖以晶圓半徑對RO速度為例,基於電壓補償與製程偏移的等效性原理,能將晶圓級的不平坦性整體抬升或下降(所以只要leakage能控制,global variation並不要命),但這個技巧無法撫平晶片內的效能梯度(local variation)。

4.3.1. Process Variation Analysis
解決方式是透過硬體偵測電路與量測數據分析晶片性能梯度(gradient),運用機器學習與回歸模型(regression)推論該製程真實必須防守的實體設計餘量(margin)與時序簽核策略(sign-off strategy)。下圖是一片晶圓內(WIW),晶片對晶片(DTD)性能比(early/late)的分佈,DTD的變異性可能已經涵蓋global(但這並不可怕)。

4.3.2. D0 Derating Regression
在當前各晶圓廠普遍製程掌控與SPICE模型準確度無法有效改善的情况下,實體設計必須以科學的方法得到更符合現實的防守策略。基於成本考量,在一個晶片內我們可能沒有太多製程監測器(on-chip process monitor)的開銷空間,因此一個變通的方法如下圖。

在相同的一片晶圓元上,我們可以量測相鄰晶片(adjacent die)間RO對RO均值的梯度,再透過數個離散點的數據執行回歸分析,以間接得到晶片內或所謂D0的OCV最小要求。同一晶圓上以相鄰4×4=16晶片格子內有C(16,2)=120種組合,離散距離也會産生√2、√5、√10、√13等等許多種數據。隨著芯片間相鄰距離逐漸縮小,小到接近零的情况下,趨勢會逐漸回歸到一個範圍也就是D0 OCV(因爲沒有隨機性所以不能以LVF來防守)。
4.3.3. Efficiency & Productivity Compromise
上述D0 OCV設置直接影響良率與晶片競爭力,而這個防守範圍必須跟實體設計的各項開銷(例如晶片面積、功耗與turnaround time等等)與我們想要拿到的量產良率之間取得妥協。以下圖爲例,紅/藍色的離散點是各個距離下OCV散布的2σ邊界。在距離較遠處呈現明顯的log-normal分佈(early分佈較小,late分佈呈長尾),隨著距離縮小分佈接近skew-normal。下圖分別取落在不同PCM區域的三片具代表性晶圓與其2σ OCV分佈的回歸分析,其中有些晶圓D0 derating early/late甚至超過3.3%/4.2%,顯然這會讓P&R增加非常多的面積去扛hold time的問題。


一個折衷方案是考慮系統架構參與調節的可能性來拆分design margin,例如搭配binning策略或電壓補償分擔實體設計需要(合理)的防守餘量。例如讓P&R試圖僅對抗1.65σ變異以守住大部分體質(majority),其餘透過優化的晶片評等(binning)與電壓補償策略來彌補。
4.3.4. SPICE-Silicon Correlation
透過內崁的晶片監測電路(on-chip process monitor)與大數據分析,執行後矽與SPICE模型的關聯性分析,追蹤/推論SPICE的偏移與變異性並具體反映至實體設計配方與時序簽核的方法。 搭配過機器學習,著重晶片關鍵路徑/瓶頸與SPICE模擬的關聯性分析,對照晶片實際效能分佈與SPICE Monte分析結果建模以推估良率並給予實體設計配方與時序簽核正向反饋。

5. 機器學習框架(Machine-learning Framework)
5.1. 機器學習的工作思維(DFE/D4I)
回顧近三十年來半導體產業思維的轉移,從早期的工廠量產製造(DFM/DFT)、追求成本效益與產能(DFY)到車用電子對可靠性的要求(DFR/DFS),未來肯定會繼續往「極致能效設計(Design for Efficiency, DFE)」這個思維拓展,這個目標其實可以想成是「4個I的設計思維(D4I)」: 即Information、Intelligence、Insight與Innovation的思維過程。將數據(data)整理成表單(information),在多維度的資料間產生關聯性分析以後資料開始產生有用的情報(intelligence),透過回歸分析與機器學習(或深度學習)我們開始對資料產生了趨勢分析與洞見(insight),最後反饋到實體設計與製程優化的各個環節我們於是產生了許多新的發明(innovation)。

首先,我們的工作心態必須從「不可能」調整成「如何能」與「怎麼利用數據與機器學習」進行反饋與優化。傳統外包出去的WAT/CP/FT等數據,得好好規劃儲存並建置成寶貴的數據庫中心。在基礎設計方法學,必須從成本效益(cost-effective)內化為競爭力思維(competitive),思考優化內部的設計方法並創造附加價值。在關鍵軟/硬體技術方面,應推廣機器學習(或深度學習)於晶片設計,解決問題並優化半導體生產流程,包括: 建置競爭力和生產力優化平台,深化數據中心和數據科學家(對數據的趨勢與洞察力),推廣製程監控器方法學和模型關聯性分析(對物理更深層了解),充分運用機器學習框架與策略優化(製程、實體設計與量產)並反饋至半導體產業。
5.2. 數據中心與資料科學家建置
透過數據分析與數據庫建置,針對製程與元件庫時序/電性描述做特徵萃取(metric extraction),將資料視覺化、分析趨勢並產生洞見,如此我們在項目開案前(極早期)即能提供適當的製程選擇、規格/競爭力評估、關鍵元件庫開發、實體設計參數與製程配方優化等具體建議。

著重於晶片生產測試過程中各項數據的整合與關聯性分析,例如 WAT、CP、FT、Shmoo 與 SLT 等等。如此可以適當提供晶圓廠各項製程參數(例如 Isat、Ioff、Vtl)與晶片實體設計參數整合共通的語言,能夠對製程配方參數與量產策略的調整給出具體的優化方向與指導。

5.3. 跨資料維度關聯性分析(Data Correlation)
透過整合製程、設計與元件庫資料萃取、硬體偵測電路與後矽量測數據分析,運用機器學習與回歸模型推論製程真實必須防守的實體設計餘量(margin)與時序簽核策略。透過從WAT/CP/FT/SLT 等晶片生產製造過程的各項測試數據(feature)與關聯性分析,結合晶圓廠語言(Isat、Vtl等)與晶片設計語言(Performance、Leakage等)並投射到更高維的特徵(例如良率或能效),使製程與晶片設計雙方有明確/精確且一致的優化方向與目標。

5.4. 資料追蹤與策略優化
藉由強化專案與設計特徵萃取(design/metric extraction)、資料庫建置、關聯性分析與建模以及相關管控追蹤(tracking),透過各項跨資料維度之間能有效聯結與交互參照以求製程與設計能更有效協同優化。

在量產出貨方面,透過回歸建模與機器學習(或深度學習)提出優化的binning策略,我們除了能把一些不良品變成良品,我們還可以把一些良品變成「高竿」或將產品做不同的定價策略。最重要的就是要有一個正向循環(positive feedback),這些手法必須交互影響,也就是製程、設計與元件庫等各方人才未來必須要有更密切資料分享與互動,在這樣子持續運轉下我們才能實現所謂的「極致能效(efficiency)」。
近臨界電壓(Near-VT)系統與客製化(custom cell)需求並非單純元件庫供應商與晶片設計間兩者的供需問題而已,如何掌握底層製程SPICE模型不準確、製程變異性分析、科學化元件庫的變異性模型、製程與實體設計配方參數的整體優化、後矽的製程配方調校與量產策略與對後續元件庫開發優化的正向反饋是我們未來可以思考規劃的「創新技術」與「創新服務」核心。
1.2.串接電壓源系統(Voltage-stacking System)
早期我們做晶片多核心(multi-core)的時候,最怕的就是package RLC,因為當晶片同時有多個核平行運算的時候電流會很大,能否提供足夠的大電流是一回事,而當一個大電流通過這個元件時電壓降噪音(Ldi/dt)是被放大的。因此,晶片多核心運算有另外一種思路稱「串接電壓源(Voltage-stacking)」,它是把晶片串接起來,也就是說我們會把Vmin降到盡可能的低(例如低於350mV)。因為串聯結構電流是固定的,所以通過同樣的元件(package RLC)更多串接的晶片會把這些noise均攤掉。
晶片間的串接結構(voltage-stacking)形成了「電流動態平衡」的閉迴路系統(close loop),先天有良好對抗製程偏移的自我補償特性(self-voltage compensation),例如當有因製程偏慢的晶片在串接系統中,其跨壓會被動態提升以維持整個系統的電流平衡。然而其致命傷是因為熱或製程偏移導致的漏電流,因為串接系統為平衡電流反而使效能因漏電流加劇而降級的晶片分到更低的跨壓。此外任何非晶片運作生成的電流對串接系統極容易產生非預期的反效果,因此傳統的低電壓調節技術(例如,CG/DVFS/AVS)都變得非常不直覺,演算法必須對系統整體調整而非針對單晶片個別調整。針對這件事情目前論文數不多,但是它是一個值得研究的方向。
1.3.晶圓廠製程掌控能力
下圖是普遍晶片量產時可能遇到的製程平坦性問題(process uniformity),無論晶圓廠優劣或對製程工藝掌握如何,初期晶圓的平坦性大致都會呈現系統級的諧振(harmonic vibration),例如大者有非常明顯的甜甜圈或同心圓漣漪(polish/spin pattern),也有如火山錐的大斜坡或是如墨西哥帽的陡峭邊緣(sputter/film/holder)。中間程度者有如光刻過程的干涉網格狀或蛋槽的圖騰(litho/shot),程度輕者可能包含實體設計過程中電路佈局等綜效所造成的等效電壓降(density/metal/power/bump),其它細微者還有如摻雜與蝕刻等等製程綜效累積的結果(doping/etching)等等,這些影響可能都强過隨機性。
1.3.1. 系統級缺陷(Systematic Defect)
隨著有更多晶圓資料的累積,我們可以觀察當多數晶圓有著相同趨勢的圖案(pattern)後,即可逐漸釐清製程中誰是關鍵大頭(bottleneck)而不是互踢皮球。一般薄膜、CMP或各式製程設備會以不只一台機器批次執行,因此資料往往會出現分群的現象,但若當我們跑了上百片晶圓都有相同傾斜、漣漪或花瓣圖樣時,那案情可能就不單純了! (因為除非其中有一道大家都必須通過它的關鍵站點/流程)。
若我們將所有關於晶圓整體(WIW)性能的均值排序,例如CP時能得到的SIDD、RO、critical path頻率等等幾項參數的加權指標,可以發現晶片性能好壞已經先反應在晶圓級測試資料中。資料經常會呈現數個較小的分群或幾個更大的分群,且往往有相同的資料圖騰或缺陷特徵(pattern),因此當資料沒有分群將更顯怪異。我們可能會懷疑,噴嘴頭會全部堵一邊嗎? 支架(holder)都側傾一邊嗎? 都必須通過某幾台珍貴的機器嗎(e-beam)? 還是整座晶圓廠地基傾斜呢? 而晶圓廠之間能力的差異就是如何產生這些數據,分析這些數據並透過機器學習(machine-learning)或深度學習(deep-learning)以掌握各製程之間的關聯性並加以補償或優化。
不同晶圓廠間因為生產機器設備、製程方法與流程等差異,往往會有各自獨特的製程特徵而且非常明顯。而晶片位於晶圓的不同位置上可能呈現極端的效能差異(例如RO的頻率),一片晶圓的3σ分佈可能橫跨幾乎等效於全域的FF至SS corner的變異性。
1.3.2. WAT採樣點不足(WAT Sampling Issue)
下圖顯示晶圓級幾個物理特徵(feature)的曲面(例如SIDD與晶片內RO的均值),我們以傳統量產時幾個離散WAT測試點(13 site map)與其鄰近5×7(一個shot)區域的晶片來看,就可以知道傳統WAT數據是多麼不可靠了(既使是花費更高成本用所謂的78點full map)!
採樣點(sampling)不足會導致製程工程師團隊一個麻煩,例如所謂的WAT Isat/Vtl均值(mean)或中位數(median)「達標(on-target)」,事實上很有可能超過60%樣本是落在極大或極小的值域且其性能梯度(gradient)非常大,因此所謂的均值或中位數很有可能根本沒sample! 也就是說WAT數據變得非常「以偏概全」且不牢靠,我們很容易錯過真實最佳配方。而晶圓廠與實體設計如何分析局域的性能梯度並優化製程或調整設計餘量(margin),直接影響晶片的能效(efficiency),這裡的能效包含了晶片性能、競爭力、與產能(productivity)。這有賴晶圓廠與實體設計雙方共享更多測試數據,透過跨資料維度的關聯性分析與機器學習(或深度學習)來提升資料的可信度。
2. 實體設計的創新(Innovation in Physical Design)
2.1. 製程分析的創新(Process Analysis)
隨著對近臨界電壓系統(Near-VT System)技術的需求,晶片設計自己也必須具備製程分析與管理的能力(process management),不能再只單方面依賴晶圓廠提供的通用設計規則與條件限制。晶片設計也要有能力去分析WAT,並且根據WAT與後矽(post-silicon)測量結果去定義實體設計配方與時序簽核策略(timing sign-off)。當前製程工藝下,各家晶圓廠SPICE模型與後矽(post-silicon)資料都有明顯的偏差,若只是執行低電壓時序庫萃取(timing re-K)並依此進行實體設計可能會導致失敗。因此標準元件庫的時序特徵萃取必須分析WAT與其SPICE模型的偏移(mean shift),並依據WAT與SPICE關聯性分析具體提供校準方案、關鍵時序庫(majority corner)與相關實體設計防守策略(並依據實際市場需求與場景調整)。
2.2. 晶片關鍵路徑與SPICE模擬的關聯性分析
針對晶片電路的瓶頸(critical-path),我們可以分析並根據所使用關鍵元件各個物理參數(instance、power、area等)的占比(usage)與排序做優化,比較關鍵的IP例如memory可以透過charge-pump以保證電路存/取時的正常操作,並且對clock-network或者一些dynamic-IR比較有疑慮的點來做防守。從與許多晶圓廠於深次微米製程之量產經驗,無論製程工藝優劣,量測數據往往都無法與所提供之SPICE模型吻合(且往往偏慢)。這導致一開始有些晶圓廠可能會急著要先把製程配方(recipe)往FF方向調整(尤其是die-buy的客戶)。對晶圓廠而言他們可以較容易出貨給客戶較多「速度達標」的單晶片,但其他副作用例如漏電流(leakage)所衍生「系統能效降級」的問題卻需要客戶設法承擔,這樣的調整對整體系統層面來說並不是真實的優化。
以下圖來說明,製程調校(process tuning)在leakage維度是log增幅,再加上溫度的因素會更不好控制。事實上若晶圓廠所提供的SPICE模型(包括local variation)够準確,基於製程偏移-電壓補償的等效性,製程參數或反映在晶片速度的不達標並不可怕,透過電壓補償的手法在速度與leakage維度都是可控/可預測的〫因此,真正的最佳製程與實體設計配方應該是: 晶圓廠必須開誠布公,使製程與晶片設計雙方協調好並掌握最真實的製程參數,透過真實的防守策略進行實體設計並輔以系統層級的補償方式來「拆分對抗」變異性的難題,不要過度設計(over design)。系統設計端至少可以從實體設計配方(design recipe)與時序簽核方法學(timing sign-off)檢討,搭配晶片效能評等(binning)與電壓-頻率補償(voltage-frequency compensation)兩種策略協同優化,以降低實體設計因為over design所導致的競爭力下降(也導致所設計的晶片不夠efficient)。
2.3. 客製化元件的創新(Custom Cell/re-K)
藉由製程分析的創新(Process Analysis),我們可以根據前面所提到個別晶圓廠製程上的不同弱點(1.3.2),進行客製化元件開發(custom cell)與優化,並根據WAT的偏移修正元件庫時序萃取(timing re-K)並優化實體設計防守配方(design/sign-off recipe)。
2.3.1. 設計與元件特徵萃取(Design/Library Metric Extraction)
透過特徵萃取並觀察其趨勢,洞悉元件參數與實體設計工具/演算法整體配合的不足,才是數據分析的優勢與開發關鍵元件庫的方向(標準元件庫開發商也不都是省油的燈)。我們可以依據晶片架構與市場競爭力需求,針對不同功能性單元提供適配的關鍵元件庫規劃與開發,在滿足能效的市場規格下進一步優化面積與功耗,提升自己產品或客戶的價值。
2.3.2. 元件架構的創新
透過電路關鍵路徑與關鍵瓶頸分析排序的元件優化與開發策略,根據實際系統任務與市場需求,以統計的方式進行關鍵元件重新開發並實質收到巨大效果。實質的電路架構優化,包括針對晶片電路關鍵路徑上的元件做電性上驅動力平衡的補償、針對時脈平衡與穩壓(避免dynamic-IR)的時鐘樹元件調整、透過layout巧思的面積與功耗縮小、針對APR繞線問題的接腳位置優化、針對重複性與功能性的合併/整合(MEGA cell, DAC2020)並提供高度客製化元件的重新架構與再設計。
2.3.3. 針對功能/效能需求做適配性元件開發
一般最有效益的優化對象為暫存器(flip-flop)與時鐘樹元件(clock-tree cell),透過多位元暫存器堆疊除減少電容也需有效修正電訊號波形的歪斜(slew balance)、自帶耦合電容(de-cap)並搭配layout垂直排列以避免dynamic-IR,以及透過電路接腳位置的改善以減少實體設計繞線之間的疊代成本等等。其他比較可觀的優化可以針對電路任務/效能需求與市場規格做適配性的元件開發,例如提供不同高度(track)的元件並針對非時序瓶頸的區塊以細部優化面積與功耗。
3. 晶片內變異性分析(On-chip Variation Analysis)
3.1. 晶圓均勻一致性(Uniformity
在更早以前我們曾經有文章討論過晶片不平坦性的問題–ASIC Design之初(2)-我們在對抗甚麼?,在此,我們摘要如下三點。
3.1.1. 粗粒度諧波(Coarse-grained Harmonic)
我們以晶圓SIDD特徵曲面的反離散餘弦轉換(IDCT),從低頻到高頻的成份來解釋製程工藝中不平坦性的各個不同頻率成份。最低頻的成份包含前面第一章(1.3.1)所提到的傾斜(固定往某一側傾斜),很可能僅是由某幾道製程造成,例如薄膜或沉積不均。在稍微提高一些頻率可以看到每片晶圓都有相似同心圓的圖騰(pattern),這漣漪狀很可能是晶片在類似旋轉拋光時(polish/spin)專有的圖騰。這類比較低頻的諧波振盪(harmonic oscillator)圖案各家晶圓廠都有,只是程度優劣與改善應變能力不同的區別。
3.1.2. 細粒度諧波(Fine-grained Harmonic)
下圖也是幾乎所有晶圓廠都能看到的系統級圖騰,透過相同批次不同晶圓之間同物理量的疊加(去除隨機性),呈現的是晶圓在光刻過程光罩shot與shot之間的干涉圖樣(像冰箱裡的雞蛋盒),細部也可以很清楚看到光刻效應(Litho effect)除了電性上的影響(例如SIDD)也能看到實際對電路性能(或元件delay)的影響。在干涉的波峰位置SIDD偏大,而此時元件delay相對較小(偏快)。不過這個振盪的變異性相對較高頻且振幅較小,透過之前討論過的製程-電壓等效性原理(ASIC Design之初:章節2.4),一般在實體設計可以增加適當的設計餘量(design margin)來克服。
3.1.3. On-chip Variation
下圖是以更微觀的角度來看「非隨機性」的問題,我們可以透過環振電路(Ring-Oscillator, RO)反映晶片內部效能歪斜的情形,其中的效能梯度(performance gradient)是實體設計必須要扛的餘量(margin)。這也說明為什麼若晶片只有局域的製程監測器(process monitor)一般都不管用,只是花錢又浪費面積,設計餘量最重要的其實是處理「效能梯度」的問題。效能梯度可以想成是晶片供電之後先天有個等效電壓降(effective IR drop)不均的問題,無法用global corner應對(這個做法事實上既浪費晶片面積也無法解決梯度問題),因此我們必須確實防守這個「局部」且「非隨機性」的問題。這也是為何麼有些老經驗覺得用傳統OCV來做實體設計守備比較靠普的原因,我們常常說不清楚為何前一次量產沒事,然而用了新方法良率卻變差因此害怕而止步不前。
3.2. 對能效的影響(Efficiency Impact)
晶片能效(efficiency)不均是晶圓各種物理特徵曲面的不平坦所衍生的問題,若晶片在製造時位於晶圓上相對比較平坦的區域,那麼其晶片內時序變異(early & late)的分佈較小,反之OCV的分佈將非常大且不能以傳統LVF模型假設局域變異有隨機性因而能相互抵消(cancelation)的方式處理。下圖例舉三個晶片在晶圓不同位置所量測之動態表現,y軸代表量化的晶片性能指標,晶片在晶圓SIDD曲面高峰區(C區)有較高的Fmax但低頻可能跑不起來,麻煩的是donut B區還有個類似sin-wave的高低振盪,而邊緣區(A區)通常體質最差。
4. 製程與設計協同優化(Process & Design Co-optimization)
4.1. 製程監測電路整合(Process Monitor Integration)
在晶圓廠製程與晶片實體設計協同優化的流程中,關鍵的製程分析並不需要研發什麼高大尚的電路或花費昂貴的成本另外購置IP,重點應該放在: 如何「規劃」與「產生」所想分析的數據資料,以及如何進行跨資料維度的關聯分析(correlation)與建模(modeling)。透過資料科學的創新,掌握更精確的製程與設計參數,下面流程以一般常用的Ring-Oscillator(RO)為例。
RO的設計取決於我們想要得到甚麼樣的數據,例如: 為了跟SPICE對答案我們會多準備幾種單一元件組成的delay-line(若面積許可有時甚至會搭配數種不同driving),為了跟晶片效能有較佳的關聯性我們會嘗試組合幾種使用比率較高(有代表性)的元件(例如critical-path),為了能夠跟WAT有較好的關聯性我們會配置至少兩種P-stacking與N-stacking的元件,其他諸如為了取得對電壓較或對溫度較有敏感性的特徵我們會客製化一些特殊元件來當作RO的組成要件。
4.2. Co-optimization Flow
以目前各家晶圓廠的製程控制能力與配合度,實務面來看不太可能只靠系統端binning策略或電壓補償就可以明顯改善能效目標(J/TOPs)。下圖是給期許未來能搭載數據分析與製程控制能力的晶片設計公司一個建議的實體設計與製程協同優化的流程,目標是透過製程分析與機器學習(或深度學習)提出策略並正向回饋以優化元件庫與實體設計方法學,使每次疊代都能具體提升至少10%能效目標。
4.3. 晶片內變異性的設計餘量(OCV Margin)
實體設計須優先考慮真實的OCV防守餘量,雖然這只是局域的變異性(local variation)但却是晶片生產結果的大宗(majority),會發生且為非隨機性的變異(系統級),也應該是最低設計要求(minimum requirement)。基本的OCV需求若沒守住,global corner加再多設計餘量(margin),搭配怎麼優秀的binning或電壓補償可能都沒有用! 如下圖以晶圓半徑對RO速度為例,基於電壓補償與製程偏移的等效性原理,能將晶圓級的不平坦性整體抬升或下降(所以只要leakage能控制,global variation並不要命),但這個技巧無法撫平晶片內的效能梯度(local variation)。
4.3.1. Process Variation Analysis
解決方式是透過硬體偵測電路與量測數據分析晶片性能梯度(gradient),運用機器學習與回歸模型(regression)推論該製程真實必須防守的實體設計餘量(margin)與時序簽核策略(sign-off strategy)。下圖是一片晶圓內(WIW),晶片對晶片(DTD)性能比(early/late)的分佈,DTD的變異性可能已經涵蓋global(但這並不可怕)。
4.3.2. D0 Derating Regression
在當前各晶圓廠普遍製程掌控與SPICE模型準確度無法有效改善的情况下,實體設計必須以科學的方法得到更符合現實的防守策略。基於成本考量,在一個晶片內我們可能沒有太多製程監測器(on-chip process monitor)的開銷空間,因此一個變通的方法如下圖。
在相同的一片晶圓元上,我們可以量測相鄰晶片(adjacent die)間RO對RO均值的梯度,再透過數個離散點的數據執行回歸分析,以間接得到晶片內或所謂D0的OCV最小要求。同一晶圓上以相鄰4×4=16晶片格子內有C(16,2)=120種組合,離散距離也會産生√2、√5、√10、√13等等許多種數據。隨著芯片間相鄰距離逐漸縮小,小到接近零的情况下,趨勢會逐漸回歸到一個範圍也就是D0 OCV(因爲沒有隨機性所以不能以LVF來防守)。
4.3.3. Efficiency & Productivity Compromise
上述D0 OCV設置直接影響良率與晶片競爭力,而這個防守範圍必須跟實體設計的各項開銷(例如晶片面積、功耗與turnaround time等等)與我們想要拿到的量產良率之間取得妥協。以下圖爲例,紅/藍色的離散點是各個距離下OCV散布的2σ邊界。在距離較遠處呈現明顯的log-normal分佈(early分佈較小,late分佈呈長尾),隨著距離縮小分佈接近skew-normal。下圖分別取落在不同PCM區域的三片具代表性晶圓與其2σ OCV分佈的回歸分析,其中有些晶圓D0 derating early/late甚至超過3.3%/4.2%,顯然這會讓P&R增加非常多的面積去扛hold time的問題。
一個折衷方案是考慮系統架構參與調節的可能性來拆分design margin,例如搭配binning策略或電壓補償分擔實體設計需要(合理)的防守餘量。例如讓P&R試圖僅對抗1.65σ變異以守住大部分體質(majority),其餘透過優化的晶片評等(binning)與電壓補償策略來彌補。
4.3.4. SPICE-Silicon Correlation
透過內崁的晶片監測電路(on-chip process monitor)與大數據分析,執行後矽與SPICE模型的關聯性分析,追蹤/推論SPICE的偏移與變異性並具體反映至實體設計配方與時序簽核的方法。 搭配過機器學習,著重晶片關鍵路徑/瓶頸與SPICE模擬的關聯性分析,對照晶片實際效能分佈與SPICE Monte分析結果建模以推估良率並給予實體設計配方與時序簽核正向反饋。
5. 機器學習框架(Machine-learning Framework)
5.1. 機器學習的工作思維(DFE/D4I)
回顧近三十年來半導體產業思維的轉移,從早期的工廠量產製造(DFM/DFT)、追求成本效益與產能(DFY)到車用電子對可靠性的要求(DFR/DFS),未來肯定會繼續往「極致能效設計(Design for Efficiency, DFE)」這個思維拓展,這個目標其實可以想成是「4個I的設計思維(D4I)」: 即Information、Intelligence、Insight與Innovation的思維過程。將數據(data)整理成表單(information),在多維度的資料間產生關聯性分析以後資料開始產生有用的情報(intelligence),透過回歸分析與機器學習(或深度學習)我們開始對資料產生了趨勢分析與洞見(insight),最後反饋到實體設計與製程優化的各個環節我們於是產生了許多新的發明(innovation)。
首先,我們的工作心態必須從「不可能」調整成「如何能」與「怎麼利用數據與機器學習」進行反饋與優化。傳統外包出去的WAT/CP/FT等數據,得好好規劃儲存並建置成寶貴的數據庫中心。在基礎設計方法學,必須從成本效益(cost-effective)內化為競爭力思維(competitive),思考優化內部的設計方法並創造附加價值。在關鍵軟/硬體技術方面,應推廣機器學習(或深度學習)於晶片設計,解決問題並優化半導體生產流程,包括: 建置競爭力和生產力優化平台,深化數據中心和數據科學家(對數據的趨勢與洞察力),推廣製程監控器方法學和模型關聯性分析(對物理更深層了解),充分運用機器學習框架與策略優化(製程、實體設計與量產)並反饋至半導體產業。
5.2. 數據中心與資料科學家建置
透過數據分析與數據庫建置,針對製程與元件庫時序/電性描述做特徵萃取(metric extraction),將資料視覺化、分析趨勢並產生洞見,如此我們在項目開案前(極早期)即能提供適當的製程選擇、規格/競爭力評估、關鍵元件庫開發、實體設計參數與製程配方優化等具體建議。
著重於晶片生產測試過程中各項數據的整合與關聯性分析,例如 WAT、CP、FT、Shmoo 與 SLT 等等。如此可以適當提供晶圓廠各項製程參數(例如 Isat、Ioff、Vtl)與晶片實體設計參數整合共通的語言,能夠對製程配方參數與量產策略的調整給出具體的優化方向與指導。
5.3. 跨資料維度關聯性分析(Data Correlation)
透過整合製程、設計與元件庫資料萃取、硬體偵測電路與後矽量測數據分析,運用機器學習與回歸模型推論製程真實必須防守的實體設計餘量(margin)與時序簽核策略。透過從WAT/CP/FT/SLT 等晶片生產製造過程的各項測試數據(feature)與關聯性分析,結合晶圓廠語言(Isat、Vtl等)與晶片設計語言(Performance、Leakage等)並投射到更高維的特徵(例如良率或能效),使製程與晶片設計雙方有明確/精確且一致的優化方向與目標。
5.4. 資料追蹤與策略優化
藉由強化專案與設計特徵萃取(design/metric extraction)、資料庫建置、關聯性分析與建模以及相關管控追蹤(tracking),透過各項跨資料維度之間能有效聯結與交互參照以求製程與設計能更有效協同優化。
在量產出貨方面,透過回歸建模與機器學習(或深度學習)提出優化的binning策略,我們除了能把一些不良品變成良品,我們還可以把一些良品變成「高竿」或將產品做不同的定價策略。最重要的就是要有一個正向循環(positive feedback),這些手法必須交互影響,也就是製程、設計與元件庫等各方人才未來必須要有更密切資料分享與互動,在這樣子持續運轉下我們才能實現所謂的「極致能效(efficiency)」。
近臨界電壓(Near-VT)系統與客製化(custom cell)需求並非單純元件庫供應商與晶片設計間兩者的供需問題而已,如何掌握底層製程SPICE模型不準確、製程變異性分析、科學化元件庫的變異性模型、製程與實體設計配方參數的整體優化、後矽的製程配方調校與量產策略與對後續元件庫開發優化的正向反饋是我們未來可以思考規劃的「創新技術」與「創新服務」核心。
1.3.1. 系統級缺陷(Systematic Defect)
隨著有更多晶圓資料的累積,我們可以觀察當多數晶圓有著相同趨勢的圖案(pattern)後,即可逐漸釐清製程中誰是關鍵大頭(bottleneck)而不是互踢皮球。一般薄膜、CMP或各式製程設備會以不只一台機器批次執行,因此資料往往會出現分群的現象,但若當我們跑了上百片晶圓都有相同傾斜、漣漪或花瓣圖樣時,那案情可能就不單純了! (因為除非其中有一道大家都必須通過它的關鍵站點/流程)。
若我們將所有關於晶圓整體(WIW)性能的均值排序,例如CP時能得到的SIDD、RO、critical path頻率等等幾項參數的加權指標,可以發現晶片性能好壞已經先反應在晶圓級測試資料中。資料經常會呈現數個較小的分群或幾個更大的分群,且往往有相同的資料圖騰或缺陷特徵(pattern),因此當資料沒有分群將更顯怪異。我們可能會懷疑,噴嘴頭會全部堵一邊嗎? 支架(holder)都側傾一邊嗎? 都必須通過某幾台珍貴的機器嗎(e-beam)? 還是整座晶圓廠地基傾斜呢? 而晶圓廠之間能力的差異就是如何產生這些數據,分析這些數據並透過機器學習(machine-learning)或深度學習(deep-learning)以掌握各製程之間的關聯性並加以補償或優化。
不同晶圓廠間因為生產機器設備、製程方法與流程等差異,往往會有各自獨特的製程特徵而且非常明顯。而晶片位於晶圓的不同位置上可能呈現極端的效能差異(例如RO的頻率),一片晶圓的3σ分佈可能橫跨幾乎等效於全域的FF至SS corner的變異性。
1.3.2. WAT採樣點不足(WAT Sampling Issue)
下圖顯示晶圓級幾個物理特徵(feature)的曲面(例如SIDD與晶片內RO的均值),我們以傳統量產時幾個離散WAT測試點(13 site map)與其鄰近5×7(一個shot)區域的晶片來看,就可以知道傳統WAT數據是多麼不可靠了(既使是花費更高成本用所謂的78點full map)!
採樣點(sampling)不足會導致製程工程師團隊一個麻煩,例如所謂的WAT Isat/Vtl均值(mean)或中位數(median)「達標(on-target)」,事實上很有可能超過60%樣本是落在極大或極小的值域且其性能梯度(gradient)非常大,因此所謂的均值或中位數很有可能根本沒sample! 也就是說WAT數據變得非常「以偏概全」且不牢靠,我們很容易錯過真實最佳配方。而晶圓廠與實體設計如何分析局域的性能梯度並優化製程或調整設計餘量(margin),直接影響晶片的能效(efficiency),這裡的能效包含了晶片性能、競爭力、與產能(productivity)。這有賴晶圓廠與實體設計雙方共享更多測試數據,透過跨資料維度的關聯性分析與機器學習(或深度學習)來提升資料的可信度。
2. 實體設計的創新(Innovation in Physical Design)
2.1. 製程分析的創新(Process Analysis)
隨著對近臨界電壓系統(Near-VT System)技術的需求,晶片設計自己也必須具備製程分析與管理的能力(process management),不能再只單方面依賴晶圓廠提供的通用設計規則與條件限制。晶片設計也要有能力去分析WAT,並且根據WAT與後矽(post-silicon)測量結果去定義實體設計配方與時序簽核策略(timing sign-off)。當前製程工藝下,各家晶圓廠SPICE模型與後矽(post-silicon)資料都有明顯的偏差,若只是執行低電壓時序庫萃取(timing re-K)並依此進行實體設計可能會導致失敗。因此標準元件庫的時序特徵萃取必須分析WAT與其SPICE模型的偏移(mean shift),並依據WAT與SPICE關聯性分析具體提供校準方案、關鍵時序庫(majority corner)與相關實體設計防守策略(並依據實際市場需求與場景調整)。
2.2. 晶片關鍵路徑與SPICE模擬的關聯性分析
針對晶片電路的瓶頸(critical-path),我們可以分析並根據所使用關鍵元件各個物理參數(instance、power、area等)的占比(usage)與排序做優化,比較關鍵的IP例如memory可以透過charge-pump以保證電路存/取時的正常操作,並且對clock-network或者一些dynamic-IR比較有疑慮的點來做防守。從與許多晶圓廠於深次微米製程之量產經驗,無論製程工藝優劣,量測數據往往都無法與所提供之SPICE模型吻合(且往往偏慢)。這導致一開始有些晶圓廠可能會急著要先把製程配方(recipe)往FF方向調整(尤其是die-buy的客戶)。對晶圓廠而言他們可以較容易出貨給客戶較多「速度達標」的單晶片,但其他副作用例如漏電流(leakage)所衍生「系統能效降級」的問題卻需要客戶設法承擔,這樣的調整對整體系統層面來說並不是真實的優化。
以下圖來說明,製程調校(process tuning)在leakage維度是log增幅,再加上溫度的因素會更不好控制。事實上若晶圓廠所提供的SPICE模型(包括local variation)够準確,基於製程偏移-電壓補償的等效性,製程參數或反映在晶片速度的不達標並不可怕,透過電壓補償的手法在速度與leakage維度都是可控/可預測的〫因此,真正的最佳製程與實體設計配方應該是: 晶圓廠必須開誠布公,使製程與晶片設計雙方協調好並掌握最真實的製程參數,透過真實的防守策略進行實體設計並輔以系統層級的補償方式來「拆分對抗」變異性的難題,不要過度設計(over design)。系統設計端至少可以從實體設計配方(design recipe)與時序簽核方法學(timing sign-off)檢討,搭配晶片效能評等(binning)與電壓-頻率補償(voltage-frequency compensation)兩種策略協同優化,以降低實體設計因為over design所導致的競爭力下降(也導致所設計的晶片不夠efficient)。
2.3. 客製化元件的創新(Custom Cell/re-K)
藉由製程分析的創新(Process Analysis),我們可以根據前面所提到個別晶圓廠製程上的不同弱點(1.3.2),進行客製化元件開發(custom cell)與優化,並根據WAT的偏移修正元件庫時序萃取(timing re-K)並優化實體設計防守配方(design/sign-off recipe)。
2.3.1. 設計與元件特徵萃取(Design/Library Metric Extraction)
透過特徵萃取並觀察其趨勢,洞悉元件參數與實體設計工具/演算法整體配合的不足,才是數據分析的優勢與開發關鍵元件庫的方向(標準元件庫開發商也不都是省油的燈)。我們可以依據晶片架構與市場競爭力需求,針對不同功能性單元提供適配的關鍵元件庫規劃與開發,在滿足能效的市場規格下進一步優化面積與功耗,提升自己產品或客戶的價值。
2.3.2. 元件架構的創新
透過電路關鍵路徑與關鍵瓶頸分析排序的元件優化與開發策略,根據實際系統任務與市場需求,以統計的方式進行關鍵元件重新開發並實質收到巨大效果。實質的電路架構優化,包括針對晶片電路關鍵路徑上的元件做電性上驅動力平衡的補償、針對時脈平衡與穩壓(避免dynamic-IR)的時鐘樹元件調整、透過layout巧思的面積與功耗縮小、針對APR繞線問題的接腳位置優化、針對重複性與功能性的合併/整合(MEGA cell, DAC2020)並提供高度客製化元件的重新架構與再設計。
2.3.3. 針對功能/效能需求做適配性元件開發
一般最有效益的優化對象為暫存器(flip-flop)與時鐘樹元件(clock-tree cell),透過多位元暫存器堆疊除減少電容也需有效修正電訊號波形的歪斜(slew balance)、自帶耦合電容(de-cap)並搭配layout垂直排列以避免dynamic-IR,以及透過電路接腳位置的改善以減少實體設計繞線之間的疊代成本等等。其他比較可觀的優化可以針對電路任務/效能需求與市場規格做適配性的元件開發,例如提供不同高度(track)的元件並針對非時序瓶頸的區塊以細部優化面積與功耗。
3. 晶片內變異性分析(On-chip Variation Analysis)
3.1. 晶圓均勻一致性(Uniformity
在更早以前我們曾經有文章討論過晶片不平坦性的問題–ASIC Design之初(2)-我們在對抗甚麼?,在此,我們摘要如下三點。
3.1.1. 粗粒度諧波(Coarse-grained Harmonic)
我們以晶圓SIDD特徵曲面的反離散餘弦轉換(IDCT),從低頻到高頻的成份來解釋製程工藝中不平坦性的各個不同頻率成份。最低頻的成份包含前面第一章(1.3.1)所提到的傾斜(固定往某一側傾斜),很可能僅是由某幾道製程造成,例如薄膜或沉積不均。在稍微提高一些頻率可以看到每片晶圓都有相似同心圓的圖騰(pattern),這漣漪狀很可能是晶片在類似旋轉拋光時(polish/spin)專有的圖騰。這類比較低頻的諧波振盪(harmonic oscillator)圖案各家晶圓廠都有,只是程度優劣與改善應變能力不同的區別。
3.1.2. 細粒度諧波(Fine-grained Harmonic)
下圖也是幾乎所有晶圓廠都能看到的系統級圖騰,透過相同批次不同晶圓之間同物理量的疊加(去除隨機性),呈現的是晶圓在光刻過程光罩shot與shot之間的干涉圖樣(像冰箱裡的雞蛋盒),細部也可以很清楚看到光刻效應(Litho effect)除了電性上的影響(例如SIDD)也能看到實際對電路性能(或元件delay)的影響。在干涉的波峰位置SIDD偏大,而此時元件delay相對較小(偏快)。不過這個振盪的變異性相對較高頻且振幅較小,透過之前討論過的製程-電壓等效性原理(ASIC Design之初:章節2.4),一般在實體設計可以增加適當的設計餘量(design margin)來克服。
3.1.3. On-chip Variation
下圖是以更微觀的角度來看「非隨機性」的問題,我們可以透過環振電路(Ring-Oscillator, RO)反映晶片內部效能歪斜的情形,其中的效能梯度(performance gradient)是實體設計必須要扛的餘量(margin)。這也說明為什麼若晶片只有局域的製程監測器(process monitor)一般都不管用,只是花錢又浪費面積,設計餘量最重要的其實是處理「效能梯度」的問題。效能梯度可以想成是晶片供電之後先天有個等效電壓降(effective IR drop)不均的問題,無法用global corner應對(這個做法事實上既浪費晶片面積也無法解決梯度問題),因此我們必須確實防守這個「局部」且「非隨機性」的問題。這也是為何麼有些老經驗覺得用傳統OCV來做實體設計守備比較靠普的原因,我們常常說不清楚為何前一次量產沒事,然而用了新方法良率卻變差因此害怕而止步不前。
3.2. 對能效的影響(Efficiency Impact)
晶片能效(efficiency)不均是晶圓各種物理特徵曲面的不平坦所衍生的問題,若晶片在製造時位於晶圓上相對比較平坦的區域,那麼其晶片內時序變異(early & late)的分佈較小,反之OCV的分佈將非常大且不能以傳統LVF模型假設局域變異有隨機性因而能相互抵消(cancelation)的方式處理。下圖例舉三個晶片在晶圓不同位置所量測之動態表現,y軸代表量化的晶片性能指標,晶片在晶圓SIDD曲面高峰區(C區)有較高的Fmax但低頻可能跑不起來,麻煩的是donut B區還有個類似sin-wave的高低振盪,而邊緣區(A區)通常體質最差。
4. 製程與設計協同優化(Process & Design Co-optimization)
4.1. 製程監測電路整合(Process Monitor Integration)
在晶圓廠製程與晶片實體設計協同優化的流程中,關鍵的製程分析並不需要研發什麼高大尚的電路或花費昂貴的成本另外購置IP,重點應該放在: 如何「規劃」與「產生」所想分析的數據資料,以及如何進行跨資料維度的關聯分析(correlation)與建模(modeling)。透過資料科學的創新,掌握更精確的製程與設計參數,下面流程以一般常用的Ring-Oscillator(RO)為例。
RO的設計取決於我們想要得到甚麼樣的數據,例如: 為了跟SPICE對答案我們會多準備幾種單一元件組成的delay-line(若面積許可有時甚至會搭配數種不同driving),為了跟晶片效能有較佳的關聯性我們會嘗試組合幾種使用比率較高(有代表性)的元件(例如critical-path),為了能夠跟WAT有較好的關聯性我們會配置至少兩種P-stacking與N-stacking的元件,其他諸如為了取得對電壓較或對溫度較有敏感性的特徵我們會客製化一些特殊元件來當作RO的組成要件。
4.2. Co-optimization Flow
以目前各家晶圓廠的製程控制能力與配合度,實務面來看不太可能只靠系統端binning策略或電壓補償就可以明顯改善能效目標(J/TOPs)。下圖是給期許未來能搭載數據分析與製程控制能力的晶片設計公司一個建議的實體設計與製程協同優化的流程,目標是透過製程分析與機器學習(或深度學習)提出策略並正向回饋以優化元件庫與實體設計方法學,使每次疊代都能具體提升至少10%能效目標。
4.3. 晶片內變異性的設計餘量(OCV Margin)
實體設計須優先考慮真實的OCV防守餘量,雖然這只是局域的變異性(local variation)但却是晶片生產結果的大宗(majority),會發生且為非隨機性的變異(系統級),也應該是最低設計要求(minimum requirement)。基本的OCV需求若沒守住,global corner加再多設計餘量(margin),搭配怎麼優秀的binning或電壓補償可能都沒有用! 如下圖以晶圓半徑對RO速度為例,基於電壓補償與製程偏移的等效性原理,能將晶圓級的不平坦性整體抬升或下降(所以只要leakage能控制,global variation並不要命),但這個技巧無法撫平晶片內的效能梯度(local variation)。
4.3.1. Process Variation Analysis
解決方式是透過硬體偵測電路與量測數據分析晶片性能梯度(gradient),運用機器學習與回歸模型(regression)推論該製程真實必須防守的實體設計餘量(margin)與時序簽核策略(sign-off strategy)。下圖是一片晶圓內(WIW),晶片對晶片(DTD)性能比(early/late)的分佈,DTD的變異性可能已經涵蓋global(但這並不可怕)。
4.3.2. D0 Derating Regression
在當前各晶圓廠普遍製程掌控與SPICE模型準確度無法有效改善的情况下,實體設計必須以科學的方法得到更符合現實的防守策略。基於成本考量,在一個晶片內我們可能沒有太多製程監測器(on-chip process monitor)的開銷空間,因此一個變通的方法如下圖。
在相同的一片晶圓元上,我們可以量測相鄰晶片(adjacent die)間RO對RO均值的梯度,再透過數個離散點的數據執行回歸分析,以間接得到晶片內或所謂D0的OCV最小要求。同一晶圓上以相鄰4×4=16晶片格子內有C(16,2)=120種組合,離散距離也會産生√2、√5、√10、√13等等許多種數據。隨著芯片間相鄰距離逐漸縮小,小到接近零的情况下,趨勢會逐漸回歸到一個範圍也就是D0 OCV(因爲沒有隨機性所以不能以LVF來防守)。
4.3.3. Efficiency & Productivity Compromise
上述D0 OCV設置直接影響良率與晶片競爭力,而這個防守範圍必須跟實體設計的各項開銷(例如晶片面積、功耗與turnaround time等等)與我們想要拿到的量產良率之間取得妥協。以下圖爲例,紅/藍色的離散點是各個距離下OCV散布的2σ邊界。在距離較遠處呈現明顯的log-normal分佈(early分佈較小,late分佈呈長尾),隨著距離縮小分佈接近skew-normal。下圖分別取落在不同PCM區域的三片具代表性晶圓與其2σ OCV分佈的回歸分析,其中有些晶圓D0 derating early/late甚至超過3.3%/4.2%,顯然這會讓P&R增加非常多的面積去扛hold time的問題。
一個折衷方案是考慮系統架構參與調節的可能性來拆分design margin,例如搭配binning策略或電壓補償分擔實體設計需要(合理)的防守餘量。例如讓P&R試圖僅對抗1.65σ變異以守住大部分體質(majority),其餘透過優化的晶片評等(binning)與電壓補償策略來彌補。
4.3.4. SPICE-Silicon Correlation
透過內崁的晶片監測電路(on-chip process monitor)與大數據分析,執行後矽與SPICE模型的關聯性分析,追蹤/推論SPICE的偏移與變異性並具體反映至實體設計配方與時序簽核的方法。 搭配過機器學習,著重晶片關鍵路徑/瓶頸與SPICE模擬的關聯性分析,對照晶片實際效能分佈與SPICE Monte分析結果建模以推估良率並給予實體設計配方與時序簽核正向反饋。
5. 機器學習框架(Machine-learning Framework)
5.1. 機器學習的工作思維(DFE/D4I)
回顧近三十年來半導體產業思維的轉移,從早期的工廠量產製造(DFM/DFT)、追求成本效益與產能(DFY)到車用電子對可靠性的要求(DFR/DFS),未來肯定會繼續往「極致能效設計(Design for Efficiency, DFE)」這個思維拓展,這個目標其實可以想成是「4個I的設計思維(D4I)」: 即Information、Intelligence、Insight與Innovation的思維過程。將數據(data)整理成表單(information),在多維度的資料間產生關聯性分析以後資料開始產生有用的情報(intelligence),透過回歸分析與機器學習(或深度學習)我們開始對資料產生了趨勢分析與洞見(insight),最後反饋到實體設計與製程優化的各個環節我們於是產生了許多新的發明(innovation)。
首先,我們的工作心態必須從「不可能」調整成「如何能」與「怎麼利用數據與機器學習」進行反饋與優化。傳統外包出去的WAT/CP/FT等數據,得好好規劃儲存並建置成寶貴的數據庫中心。在基礎設計方法學,必須從成本效益(cost-effective)內化為競爭力思維(competitive),思考優化內部的設計方法並創造附加價值。在關鍵軟/硬體技術方面,應推廣機器學習(或深度學習)於晶片設計,解決問題並優化半導體生產流程,包括: 建置競爭力和生產力優化平台,深化數據中心和數據科學家(對數據的趨勢與洞察力),推廣製程監控器方法學和模型關聯性分析(對物理更深層了解),充分運用機器學習框架與策略優化(製程、實體設計與量產)並反饋至半導體產業。
5.2. 數據中心與資料科學家建置
透過數據分析與數據庫建置,針對製程與元件庫時序/電性描述做特徵萃取(metric extraction),將資料視覺化、分析趨勢並產生洞見,如此我們在項目開案前(極早期)即能提供適當的製程選擇、規格/競爭力評估、關鍵元件庫開發、實體設計參數與製程配方優化等具體建議。
著重於晶片生產測試過程中各項數據的整合與關聯性分析,例如 WAT、CP、FT、Shmoo 與 SLT 等等。如此可以適當提供晶圓廠各項製程參數(例如 Isat、Ioff、Vtl)與晶片實體設計參數整合共通的語言,能夠對製程配方參數與量產策略的調整給出具體的優化方向與指導。
5.3. 跨資料維度關聯性分析(Data Correlation)
透過整合製程、設計與元件庫資料萃取、硬體偵測電路與後矽量測數據分析,運用機器學習與回歸模型推論製程真實必須防守的實體設計餘量(margin)與時序簽核策略。透過從WAT/CP/FT/SLT 等晶片生產製造過程的各項測試數據(feature)與關聯性分析,結合晶圓廠語言(Isat、Vtl等)與晶片設計語言(Performance、Leakage等)並投射到更高維的特徵(例如良率或能效),使製程與晶片設計雙方有明確/精確且一致的優化方向與目標。
5.4. 資料追蹤與策略優化
藉由強化專案與設計特徵萃取(design/metric extraction)、資料庫建置、關聯性分析與建模以及相關管控追蹤(tracking),透過各項跨資料維度之間能有效聯結與交互參照以求製程與設計能更有效協同優化。
在量產出貨方面,透過回歸建模與機器學習(或深度學習)提出優化的binning策略,我們除了能把一些不良品變成良品,我們還可以把一些良品變成「高竿」或將產品做不同的定價策略。最重要的就是要有一個正向循環(positive feedback),這些手法必須交互影響,也就是製程、設計與元件庫等各方人才未來必須要有更密切資料分享與互動,在這樣子持續運轉下我們才能實現所謂的「極致能效(efficiency)」。
近臨界電壓(Near-VT)系統與客製化(custom cell)需求並非單純元件庫供應商與晶片設計間兩者的供需問題而已,如何掌握底層製程SPICE模型不準確、製程變異性分析、科學化元件庫的變異性模型、製程與實體設計配方參數的整體優化、後矽的製程配方調校與量產策略與對後續元件庫開發優化的正向反饋是我們未來可以思考規劃的「創新技術」與「創新服務」核心。
首先,我們的工作心態必須從「不可能」調整成「如何能」與「怎麼利用數據與機器學習」進行反饋與優化。傳統外包出去的WAT/CP/FT等數據,得好好規劃儲存並建置成寶貴的數據庫中心。在基礎設計方法學,必須從成本效益(cost-effective)內化為競爭力思維(competitive),思考優化內部的設計方法並創造附加價值。在關鍵軟/硬體技術方面,應推廣機器學習(或深度學習)於晶片設計,解決問題並優化半導體生產流程,包括: 建置競爭力和生產力優化平台,深化數據中心和數據科學家(對數據的趨勢與洞察力),推廣製程監控器方法學和模型關聯性分析(對物理更深層了解),充分運用機器學習框架與策略優化(製程、實體設計與量產)並反饋至半導體產業。
5.2. 數據中心與資料科學家建置
透過數據分析與數據庫建置,針對製程與元件庫時序/電性描述做特徵萃取(metric extraction),將資料視覺化、分析趨勢並產生洞見,如此我們在項目開案前(極早期)即能提供適當的製程選擇、規格/競爭力評估、關鍵元件庫開發、實體設計參數與製程配方優化等具體建議。
著重於晶片生產測試過程中各項數據的整合與關聯性分析,例如 WAT、CP、FT、Shmoo 與 SLT 等等。如此可以適當提供晶圓廠各項製程參數(例如 Isat、Ioff、Vtl)與晶片實體設計參數整合共通的語言,能夠對製程配方參數與量產策略的調整給出具體的優化方向與指導。
5.3. 跨資料維度關聯性分析(Data Correlation)
透過整合製程、設計與元件庫資料萃取、硬體偵測電路與後矽量測數據分析,運用機器學習與回歸模型推論製程真實必須防守的實體設計餘量(margin)與時序簽核策略。透過從WAT/CP/FT/SLT 等晶片生產製造過程的各項測試數據(feature)與關聯性分析,結合晶圓廠語言(Isat、Vtl等)與晶片設計語言(Performance、Leakage等)並投射到更高維的特徵(例如良率或能效),使製程與晶片設計雙方有明確/精確且一致的優化方向與目標。
5.4. 資料追蹤與策略優化
藉由強化專案與設計特徵萃取(design/metric extraction)、資料庫建置、關聯性分析與建模以及相關管控追蹤(tracking),透過各項跨資料維度之間能有效聯結與交互參照以求製程與設計能更有效協同優化。
在量產出貨方面,透過回歸建模與機器學習(或深度學習)提出優化的binning策略,我們除了能把一些不良品變成良品,我們還可以把一些良品變成「高竿」或將產品做不同的定價策略。最重要的就是要有一個正向循環(positive feedback),這些手法必須交互影響,也就是製程、設計與元件庫等各方人才未來必須要有更密切資料分享與互動,在這樣子持續運轉下我們才能實現所謂的「極致能效(efficiency)」。
近臨界電壓(Near-VT)系統與客製化(custom cell)需求並非單純元件庫供應商與晶片設計間兩者的供需問題而已,如何掌握底層製程SPICE模型不準確、製程變異性分析、科學化元件庫的變異性模型、製程與實體設計配方參數的整體優化、後矽的製程配方調校與量產策略與對後續元件庫開發優化的正向反饋是我們未來可以思考規劃的「創新技術」與「創新服務」核心。



